智能教学资源知识库建设

一、 教学资源管理的核心痛点
传统教学资源管理模式正深陷效率困境:文档散乱无序、视频课程难以检索、政策文件庞杂且更新传达滞后... 这些挑战集中体现在三大核心痛点:
1. 多格式教学文档资源碎片化: 关键知识资产,包括文档(docx, pdf)、表格(excel)、演示文稿(pptx)、视频课程、音频文件等,分散存储于不同平台或路径,缺乏统一归集与有效管理,容易形成信息孤岛。
2. 结构化信息提取效率低下: 核心信息与知识点往往深埋于冗长文档或复杂文件中,依赖人工逐页查找、筛选与提炼,过程耗时耗力,效率远低于业务需求,严重制约决策速度与响应能力。
3. 海量音视频知识资产沉睡: 宝贵的教学录像、培训视频、经验分享等音视频资源未被有效激活。由于缺乏智能标签、精准检索与内容提炼手段,其内在价值难以被挖掘和复用,知识复用率与转化率极低。
这些痛点共同导致了学校知识资产的严重浪费与运营效率的瓶颈,亟需智能化、体系化的解决方案来盘活知识资源,释放其潜在价值。
二、新的解决方案:“智能教学资源知识库”
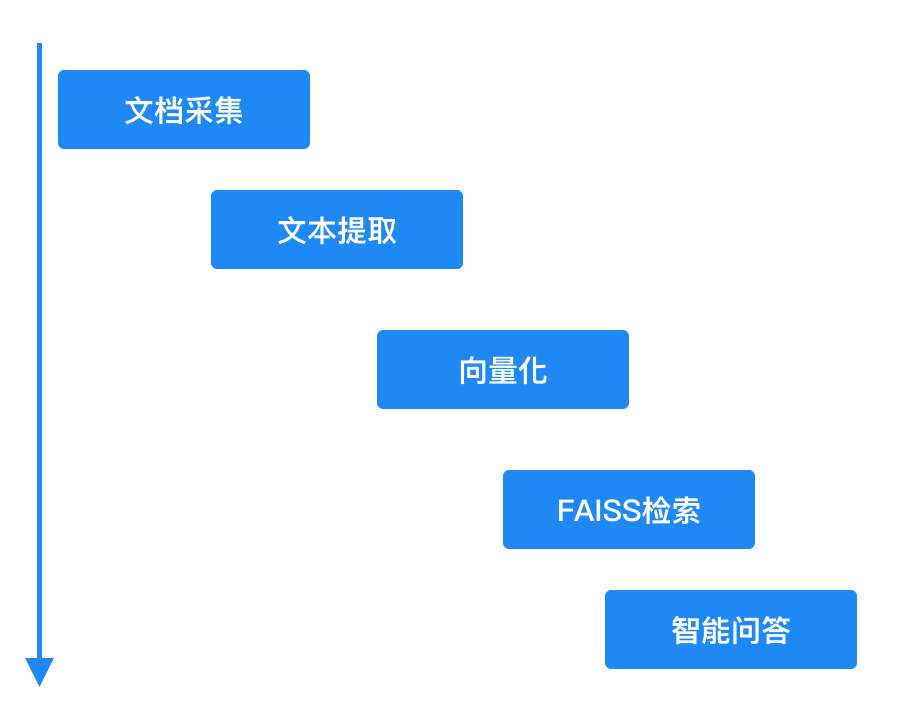
为高效激活沉睡的教学资源并释放其价值,我们创新性地设计了一套系统的知识转化流程,共分四个核心步骤:
1. 全面文档采集: 首先,系统化地采集散落在各处的原始教学资源文件(包括文档、PPT、音视频等),建立统一的资源池。
文档类 | 音视频类 |
DOCX/PDF | MP4/AVI |
Excel | MP3/WAV |
PPTX | 录播课/会议录像 |
2. 深度内容解析与文本提取: 利用先进的解析技术(如OCR、ASR、文档结构解析),对多格式内容(尤其是音视频)进行深度处理,精准提取其中的结构化/非结构化文本信息,形成文本知识池。
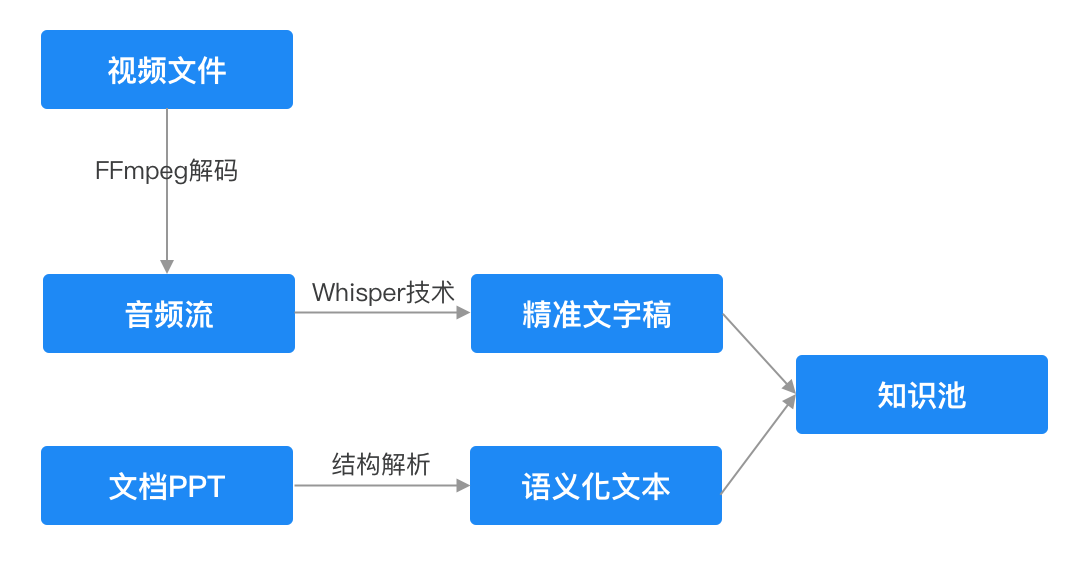
3. 语义向量化与知识表征: 借助强大的AI模型(如Embedding模型),将提取的文本信息转化为高维语义向量。这一步是关键,它能深刻理解知识的语义内涵,为智能检索奠定基础。
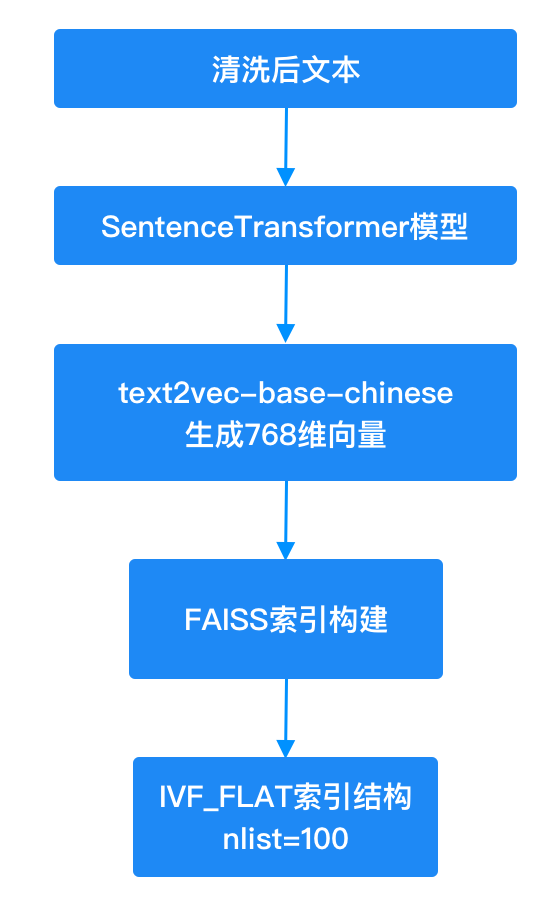
4. 构建高效向量索引(FAISS)与智能问答: 利用高性能向量数据库技术(如FAISS),对海量知识向量建立超高速索引。最终,用户可通过自然语言进行智能问答,系统能毫秒级精准定位并返回相关知识片段,实现知识的即时按需获取。
FAISS检索核心流程:
# 生成768维向量
question_vec = model.encode("学校开设的专业有哪些?")
# FAISS search函数
distances, indices = faiss_index.search(question_vec, k=3)
# 获取Top3相关片段
context = [knowledge_base[i] for i in indices[0]]
# 生成最终回答
answer = llm.generate(context, question) 通过这四步流程,沉睡的原始教学资源得以深度“知识化”,最终构建成强大的、可动态更新的教学资源知识库。这不仅极大提升了知识的可发现性与利用率,更能直接辅助教师、学生进行学习、问题解决或决策支持。
三、智能教学资源知识库场景落地价值及应用
|
场景 |
传统模式耗时 |
AI知识库方案 |
|
调取某个知识所在的文档 |
15-30分钟 |
3秒 |
|
解答教务/教学政策咨询 |
人工转接2次 |
即时回复 |
该技术的典型应用场景
答疑机器人:整合学生手册、选课指南、课程资源等文档,自动回答用户的问题。
教学资源中枢:海量课时视频秒级定位知识点,迅速定位视频文档中的知识点。
教务政策百科:实时同步多项管理制度,自动学习政策文件、规章制度文件,成为一个“教务教学百事通”。
四、应用演示
根据如上技术方案,我们依据上海市静安区业余大学的新生报名咨询文档实现了一个报名问题咨询机器人,可以自动进行报名咨询和回答用户提问,视频如何看不清楚,可以放大视频观看具体效果。